Interpretability as a new paradigm for data science
Vectors >> vibes
10/25/2025
You want to make your AI better and safer. To learn what to do, your options include eyeballing data or feeding it to an LLM. These work ok, but are expensive to scale, systematically biased, and miss unknown unknowns.
Our product uses interpretability as a new paradigm to analyze data. It’s more efficient, finds more significant insights, and captures more sophisticated concepts than existing baselines.
How it works
Interpretability techniques can be thought of as an MRI that can scan a model’s mind. Typically this MRI is used when models are talking to see if they’re hallucinating, misbehaving, or performing a character. But you can also have models look at something and read what goes through their head.
This is subtly powerful. We can search through their brain, find human-understandable concepts, and treat them like mathematical objects. We call these features. For example, anytime a model is offering sympathy, you can watch that part of its brain lighting up:
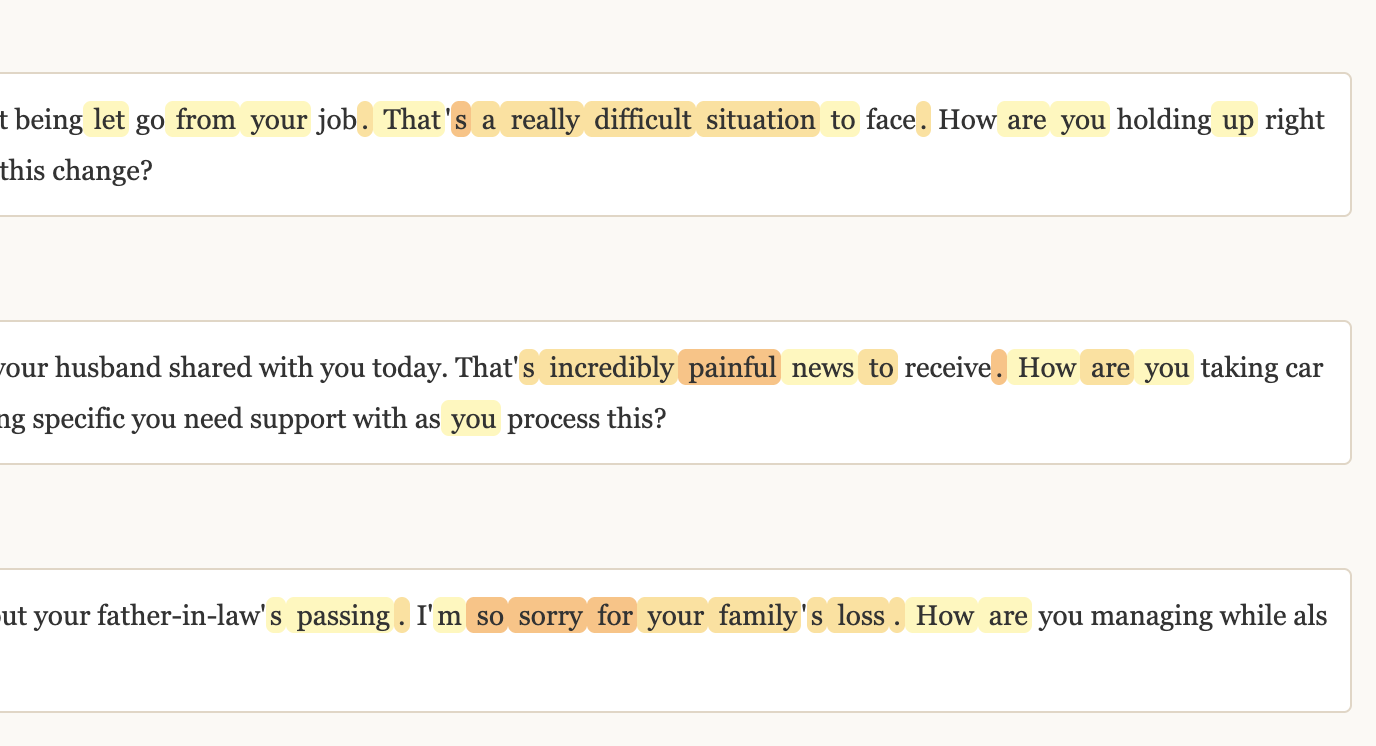
This gives us a new lens to ask questions like “what model behaviors do users like”, and “how much sympathy am I offering?”. Gutenberg’s production system uses proprietary techniques, but below are illustrations of the general approach.
Finding unknown features
Sparse auto-encoders (SAEs) are an interp technique that’s useful for discovery. You can think of them as scanning a model’s brain as it thinks about a diverse range of topics and isolating where the features are.
Features give you a sophisticated way of looking at data
Think of features as “tags” of properties for each text
- Their large dictionary of [features] provides a large hypothesis space, enabling the discovery of novel insights
- SAEs capture more than just semantic information, making them effective alternatives to traditional embeddings when we want to find properties in our dataset or group text by properties
In practice, this works pretty well
Compared to baselines… [SAEs] produce more predictive hypotheses on real datasets (∼twice as many significant findings), despite requiring 1-2 orders of magnitude less compute than recent LLM-based methods. [SAEs] also produce novel discoveries on two well-studied tasks: explaining partisan differences in Congressional speeches and identifying drivers of engagement with online headlines
We observe that the average difference for proposed hypotheses is higher for the SAE than our LLM baseline, suggesting that the SAE can discover more prominent differences between datasets
One might ask: can features help me find new patterns in user preferences? As far as we know, we are the first to apply this on with a customer in a non-academic context when we worked with a customer, Jimini Health. We found nonobvious insights in user preferences to help improve patient engagement.
The project did not involve any real patient data, due to confidentiality and privacy, and instead a simulated version of the dataset, where the Jimini team validated on their own that it translated into significant insights for them.
Finding known features
Let’s say you know what you’re looking for. Models offering sympathy, customer frustration, you name it. So you ask an LLM judge or classifier “how angry are my customers, 1-5”. This is a sensible first stab, but has problems. Judges are systematically biased and sensitive to the formatting of their prompts.
Probing (the academic term for measuring known features) has been shown to outperform judges, and can match their performance with up to 6 OOMs less compute. The intuition is: instead of having a model look at something and tell you its judgement, you have a model look at something and read its brain. If you can isolate the parts of a model responsible for reading “frustration”, it’s cheaper and more reliable to only run and measure that.
Future Improvements
Gutenberg’s technology will only get better with model improvements and interpretability breakthroughs. Features become more sophisticated as models scale. We will be able to efficiently analyze patterns over longer trajectories. New paradigms will give us even better lens for data analytics.
Fundamentally, interpretability research answers questions like “what are the mechanisms of my model, and how do they work”? A successful interpretability product answers questions like “what mechanisms lead to user satisfaction/user safety”? If you want actionable, novel insights into your AI, request a demo.