Baskerville Demo
A quick illustrative dataset
12/1/2025
Demo
Baskerville uses cutting-edge interpretability techniques to uncover insights in data that you can’t find otherwise. This kind of interp doesn’t require weight access. We’ve created a synthetic dataset to illustrate. The 3 minute video below steps through the process. The rest of the post explains the workflow in more depth.
Setup
Pretend you’re a marketing company advertising shoes. The goal is to craft messages that capture users’ interest. You have the product description and various prompts to generate SMS messages.

We have the user respond at different rates depending on the content of the message. We inject a hidden preference such that any mention of sustainability will have a significantly higher response rate.

We ensure the product description has hints to ensure eco-friendliness will make its way into the generated messages
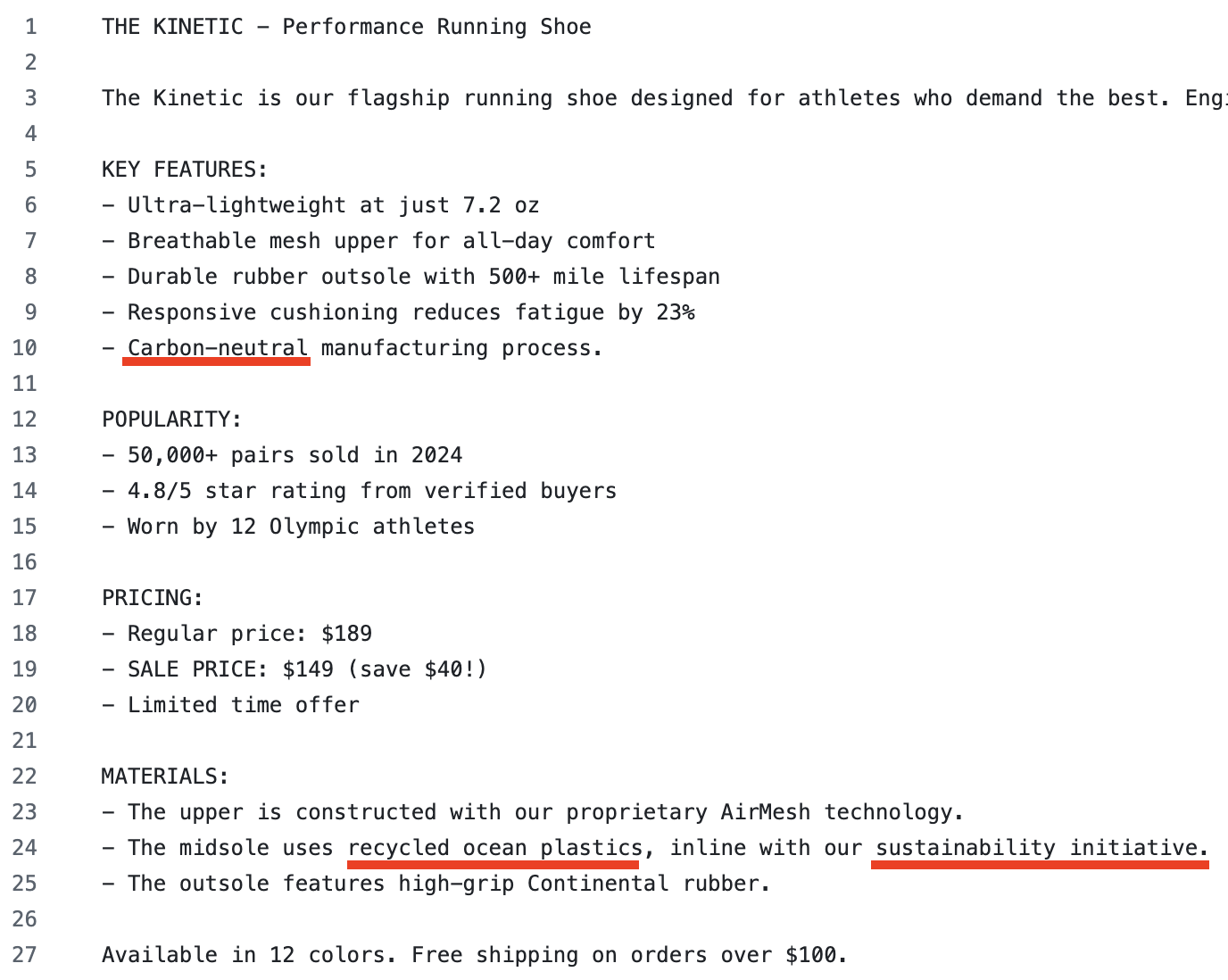
We have a debug-version of the dataset that confirms that sustainability is mentioned 23 times and interests the user 3 times, inline with the higher response rate. (From the marketing company’s perspective, they wouldn’t have this, and their data would look more like the regular dataset.)
Baselines
The regular dataset is tested against 2 baselines: LLM’s and embeddings. The methodologies are similar to data-centric interp work done earlier this year. The LLM baseline chunks the dataset into its context window (for 1000 samples, they all fit in), and is asked to surface any effective insights. It generally ends up capturing noise. The embedding baseline converts all the sequences to embeddings, then clusters them for various values of k. Then the clusters are explained with an LLM. In general, these clusters seem to collapse many concepts together
For enough differently seeded runs, or by hinting strongly enough to include “sustainability” in many messages, we expect the baselines will capture the hidden preference. But the LLM suffers from picking up a lot of noise, and embeddings + clustering ends up combining lots of features into each cluster. A priori, both baselines would be messy.
Baskerville
We provided the same dataset to our production system, Baskerville, which looks at data through features. These can be thought of as concepts that an LLM has learned to encode that interpretability techniques can extract and measure. These representations can be thought of a more sophisticated and precise version of embeddings. The methodology is explained more in depth here.
For example, the features of FOMO, social proof, and sustainability activate (highlighted in UI) whenever the concepts occur in text. We pool all samples in which they occur, and can trivially measure whether the the feature provides lift over the baseline response rate (6.7% in the dataset). The log(lift) is displayed in the top right. We can see environmentally friendliness emerges as a strong outlier feature.
Future Work
This demo illustrates that this technique already works for short documents. Baskerville has already validated with real customers that there are preferences that would go otherwise undiscovered. In particular, this is useful for consumer AI enterprises looking to better understand how users respond to their product.
We have 2 exciting future research directions: longer contexts and larger datasets. Monitoring agent traces is costly. Training datasets are too large to properly understand. Data-centric interp gives us a lens to efficiently and systematically discover biases, anomalies, and other qualities within large datasets.
Our waitlist is live here. You would be a good fit if you are
- looking to directly research data-centric interp
- or interested in dataset understanding/agent monitoring
- or an aligned enterprise looking to understand the data your model inputs/outputs, particularly paired with a target metric like customer satisfaction or agent success rate